事情是这样的。
某企业要处理一些财务数据,Excel拉出来好几千行的银行流水,要分析钱都花哪了、有没有异常交易。数据涉密,不能往ChatGPT或者deepseek这里的在线AI传。手动给Excel做数据清洗吧,翻到第三页眼睛就开始花了,而且几千行的流水你要找出哪些交易有问题可以说是很有问题的了。
于是就搞了4块V100 16G,用来搞一个纯本地的财务数据分析工具。基本功能就是 上传Excel,让AI帮忙分析,直接问"钱花哪了"就可以自动解析。
然而提需求永远是最简单的,真正落地的时候卡了我好几个月。
一、背景
先说一下为什么有这个需求。
如上文所示,有一批财务数据,主要是银行流水和会计明细账之类的,几千行起步的excel文件,涉及多个银行账户和多个月份。人工分析的话就是打开Excel,筛选清洗透视肉眼找异常,一套下来半天过去了。而且之前在EY CSDC干过,这种数据清洗真的是不想再碰一点。而且主要是这种级别的数据涉密——里面包含真实的交易对手信息、金额、账号,不可能为了图方便传到任何外网服务上。
那么市面上有没有现成的工具能满足"本地私有化部署 + Excel上传 + AI问答分析"这个组合需求呢?
很显然答案是没有(
SaaS类的数据分析工具都要求把数据上传到他们的服务器,涉密场景直接寄。开源类的工具要么只支持结构化数据库查询,要么只做简单的数据可视化,不支持自然语言问答。还有一些做AI对话的框架(比如Dify、FastGPT),可以让用户上传文档问答,但它们更适合处理文本类的知识库文档,而不是几千行带数字的表格数据——你问它"钱花哪了",它大概率给你来一段车轱辘话,因为模型本身就搞不清楚表格里的数字关系。
好吧,既然没有现成的,那就只能自己造一个。
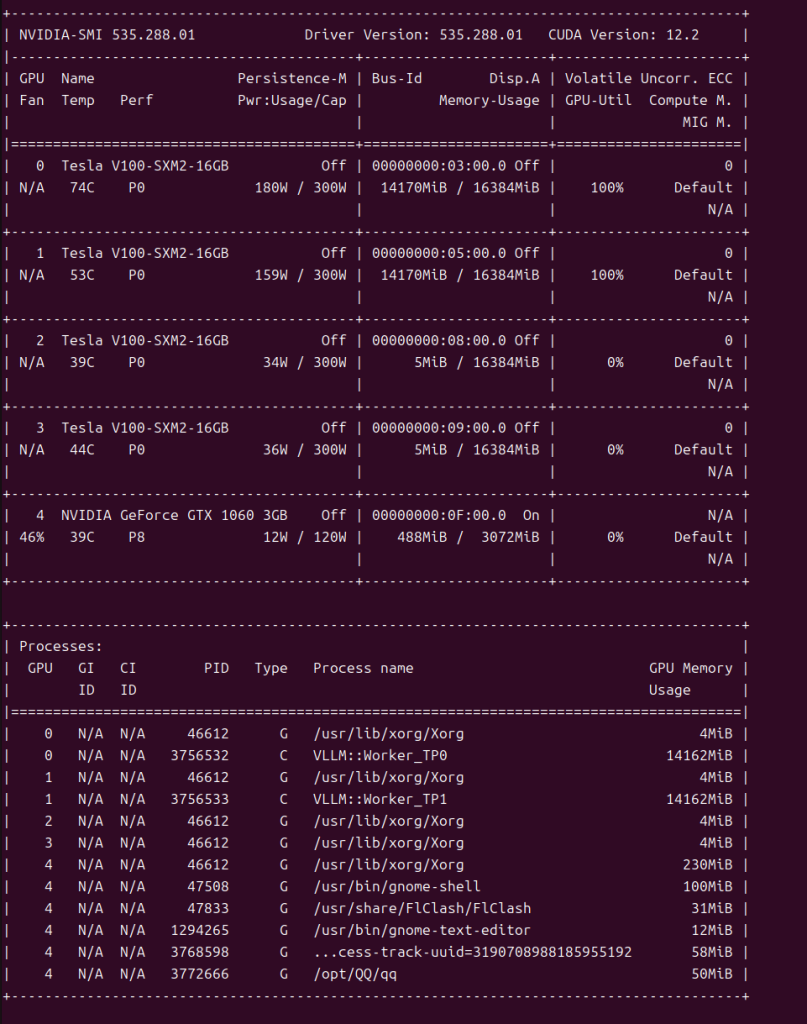
二、硬件设备介绍
先说说跑这个项目的硬件基础。
基本上是一台AI工作站,配置如下
CPU: 13th Gen Intel Core i5-13600KF,14核20线程
内存: 2×32GB DDR4-3200
主板: ASUS TUF GAMING B760M-PLUS WIFI D4
显卡:
• 4× Tesla V100-SXM2-16GB
• 1× NVIDIA GeForce GTX 1060 3GB 用来显示输出
系统: 选择的是Ubuntu 24.04
机器上有4块NVIDIA V100,16G显存每块,总共64G。用来跑大模型推理,推理框架用的是vLLM,API接口标准,好对接。而且vLLM对量化模型的支持比较成熟,要用AWQ量化版可以直接加载。
模型选的是Qwen3.5-35B-A3B-AWQ。这个选择其实综合考虑了几个因素:35B的参数规模在财务分析这种任务上够用——既要理解用户的自然语言问题,也要能对表格数据做推理和判断,太小了能力不够,太大了单机跑不动。AWQ量化版对精度损失控制得比较好,4块V100刚好能跑起来,推理速度也在可接受范围内。
本地起一个vLLM服务,监听 localhost:8000,所有后续的AI调用都走这个端口,不联网,不出内网,解决涉密问题。

三、选型
技术选型其实是边做边定的,不过最开始的技术栈就定下来了,用的是Vllm跑大模型+dify自己搓个流程图。
其实最开始有几种想法,差不多属于是同步推进的
第一种想法是:
输入→文档提取器→llm→输出
反正上下文长度是262144,足够长 不如直接把excel文件简单提取一下之后直接扔给大模型。
然后就被打脸了,给的一个示例数据比较小倒是没问题,换了一个全年的流水账就嘎嘣一下似了。

然后迭代出了第二种想法:
既然直接扔不行 那就只能用Python处理一下数据再给AI分析了。
那就从dify文档提取器节点出来之后,想办法给他格式化成格式数据。
经历了一些迭代和试错之后,最后变成这样
用户输入→文档提取器→Python数据取样→llm(拿取样的数据进行分析这段数据的格式)→llm(拿上一个总结出来的格式写一个整理全量数据的Python代码)→执行Python代码→交给llm分析→输出
这个流程看起来不错,但是实际执行的时候有两个很大的问题。
1.这样固然解决了一些上下文不够用的问题,但是我拿全年流水账测试的时候依旧还是会爆token。
2.Python清洗代码生成的随机性很高而且很慢,有的时候可以完美完成任务,有的时候就抽风生成出来的东西完全没法用。而且因为算力有限,代码生成动辄5min起步。
没办法,只能继续推翻走新的路线
最后也是第三种想法,选择了当前的技术路线:
放弃全部在dify内运行,自己写Python服务器处理数据。
后端语言不用说,Python。数据处理用pandas,Excel解析用openpyxl,AI调用走HTTP打到本地vLLM。
界面用什么纠结了一下,一开始想的是做个Web页面,前后端分离,Vue或者React写前端,FastAPI写后端。但转念一想,这项目就我一个人开发,搞前后端分离意味着要维护两套代码、两个开发环境、两套部署流程,太麻烦了。后来看到了Gradio,写一个Python文件就能生成交互式Web界面,上传文件、文本输入、Markdown展示、对话机器人这些组件都有现成的。果断选Gradio,一个人前后端全包,改个按钮文案直接在Python文件里改,不用切IDE,而且我可以完全让AI来帮我写前端(其实最后都是AI写的,写的比我好看)
架构上本来打算彻底抛弃dify,把各种LLM节点、知识库节点、代码节点拖来拖去做成流程图,看起来很美好。但实际上财务数据分析的流程没那么简单,需要先解析Excel、做数据清洗、算预聚合统计,再根据用户的问题动态构造Prompt。这些逻辑在Dify的流程节点里要么实现不了,要么写自定义代码节点变得很别扭。最终决定走自己的路线:Gradio做桌面端交互,同时把核心引擎封一层FastAPI接口,再注册到Dify当外部工具。一套引擎,三种暴露方式,桌面端能直接打开浏览器用,Dify工作流里也能调。

四、推进过程
这个路径也不是一帆风顺,而是一步步迭代成现在这样的(
最简原型,就叫他v1.0技术验证吧
第一个版本极其简陋:上传一个Excel,整个文件丢给LLM,让模型自己看数据、自己算、自己分析。结果不用想都知道,35B的模型算个合计都要想半天,遇到需要分组统计的问题更是直接寄。Token烧得飞快,一次分析消耗几千甚至上万Token,答案还不一定对。比如你问"支出最多的三个对象是谁",它可能会编几个名字出来。
那接下来就要迭代 v1.2 加预聚合层
问题很明显:LLM不擅长做精确计算,但我们让它做了大量精确计算。解决方案是在LLM前面加一层pandas预聚合——先用pandas把所有能算的都算好:数值列的合计/均值/最大/最小、按对方名称聚合的支出对象Top15、按摘要聚合的支出类型Top15、月度收支趋势。这些统计数据格式化后塞给LLM,模型只需要站在这些真实数据的基础上做分析和判断,不需要自己算数。
这一步之后效果提升非常明显。Token消耗直接降了90%以上(因为不需要让LLM读原始数据了),分析质量反而更高了(因为给的是算好的准确数据,不存在模型胡编数字的问题)。这是整个项目里最关键的一步优化。
V1.3 Prompt工程
接下来发现另一个问题:用户不太会提问题。
很少有人会准确地说"请分析2023年Q3的支出对象集中度,并标注单笔金额超过均值3倍以上的交易"。更常见的是"钱花哪了"或者"帮我看看有什么问题"。如果直接把这种模糊问1251题丢给LLM,它虽然能回答,但分析的深度和方向完全不可控。
于是做了两阶段Prompt系统:用户先输入模糊问题,LLM先把问题重写成一个结构化的分析Prompt,包含分析目标、分析维度、重点指标、输出要求四个部分。用户确认或者手动修改后,再执行正式分析。如果LLM重写失败了(比如网络问题),系统会自动降级到预先写好的领域模板库,根据关键词匹配最合适的分析模板。
(其实这个在之前的dify已经尝试过了,基本上是照搬过来但是懒的写)

同时做了四个快捷预设按钮:快速总览、资金流向、异常检测、月度趋势。点一下自动填入对应的结构化Prompt,懒得打字的时候直接用。还支持追问——分析完成后可以继续问"那这个月的异常支出呢"或者"能再具体说说第三个月的情况吗",系统会自动带上最近两轮对话的上下文。

v1.4UI迭代
有了核心功能之后开始折腾UI。最开始就是一个上传框加一个聊天框,上下排列,能用但不好看。
我又是UI苦手,所以就一股脑扔给Claudecode了。
改成了:
• 卡片式布局,三个白色卡片分区域展示(问题输入区、分析方案区、对话记录区)
• 双栏布局,左侧会话列表右侧对话内容
• 自定义颜色主题,蓝色为主色调
• 全屏模式,分析结果很长的时候可以一键展开全屏看
• 会话管理,支持重命名、删除、切换会话
(↑这段也是AI写的)
界面改到最后,虽然AI味巨浓,但是这不就是AI项目,原汤化原食,能看就行了。
v1.5多端适配
核心引擎稳定之后,又做了两件事。一是封了一层FastAPI接口,暴露五个端点(上传、分析、追问、数据统计、健康检查),这样其他服务可以通过HTTP调用同一套引擎。二是把这个API注册到Dify的PostgreSQL数据库里,Dify就能把这个API当作外部工具在工作流里使用了。同时写了个Dockerfile支持容器化部署,方便以后迁移。

到这基本就完事了 可以交差了。
虽然还有优化空间但是这点破东西花了我一个半月,累了。
五、踩坑
接下来说说踩坑吧,踩坑的密度基本和代码行数成正比。(其实也不算踩坑 主要还是前端苦手+没用过的框架+没研究明白)
一:Qwen3.5的思考过程
Qwen3.5这个模型默认会在正式回答之前输出一段思考过程。类似"嗯,用户问的是支出分析,我需要先看数据中的支出列,然后计算总额,再和收入对比……" ,而且中英混杂,放在正经的分析结果前面就很神必,客户问AI"钱花哪了",它先给来一段内心独白,然后才说结论,客户看了应该不太会开心。
网上说再prompt后面加一个/nothink ,加了 不能说有用只能说完全没用。官方文档说传 chat_template_kwargs: {enable_thinking: false} 就可以关掉这个功能。传了,没生效。查了一天文档和Issues,最后发现是vLLM版本的问题——这个参数必须在HTTP请求的JSON顶层传参,如果用 extra_body 包一层封装就不认。改完之后就解决掉了。
二:Gradio的yield和return不能混用
Gradio有一个generator模式,用yield可以实现流式输出,比如先显示"正在分析",再慢慢展示结果。但问题是generator函数里所有分支都必须用yield,如果有任何一个分支用了return而不是yield,前端就会卡死,没有任何响应。
这个bug查了我几把快两个小时,最后发现是一个错误处理分支随手写了return。改成yield之后恢复正常。
三:对话持久化
前端苦手没想好怎么存对话历史,一开始想着用浏览器的本地存储来保存,选了Gradio自带的gr.BrowserState。测了半天,刷新页面确实能恢复,但仅限于同一个页面会话内。如果关掉标签页再打开,或者部署到服务器上从另一台电脑访问,BrowserState就全丢了。因为它实际上存在前端内存里,不是真正的持久化。
最后改成后端的JSON文件持久化,反正客户就一个人用,懒的写鉴权和用户id了,每次对话更新就写文件,页面加载时重新读。简单粗暴。后来重命名、删除、切换会话的需求,都是基于这个JSON文件实现的。
四:Dropdown删除后残留值
和上面接着的,删除一个会话后,如果Dropdown当前选中的是被删掉的那个条目,Gradio会报value not in choices错误。原因是Dropdown的value还留着旧值,但choices列表里已经没有这项了。解决方案是每次删除后显式清空value。
五:JS注入卡页面
前端苦手,全屏对话功能一开始想用Gradio的head参数注入JS脚本,结果页面加载卡死。整了半天发现是Gradio 6.13的head注入机制和BrowserState插件有冲突。最后改成了在页面内容里内嵌gr.HTML组件跑JS,再配合setInterval定时器绑定DOM事件,完美解决。
六:Gradio State引用不变不触发更新
gr.State是Gradio用来在多个回调函数之间共享数据的机制。但它的变化检测机制比较特殊,如果修改的是列表或字典内部的内容(比如history[0]["content"] = "xxx"),引用不变,State检测不到变化。必须用[dict(m) for m in history]创建一个新列表来触发引用变化。
这个问题debug了很久,因为从日志看数据确实改了,但前端就是不更新。
六、最后功能总结
最终做出来的东西长这样:

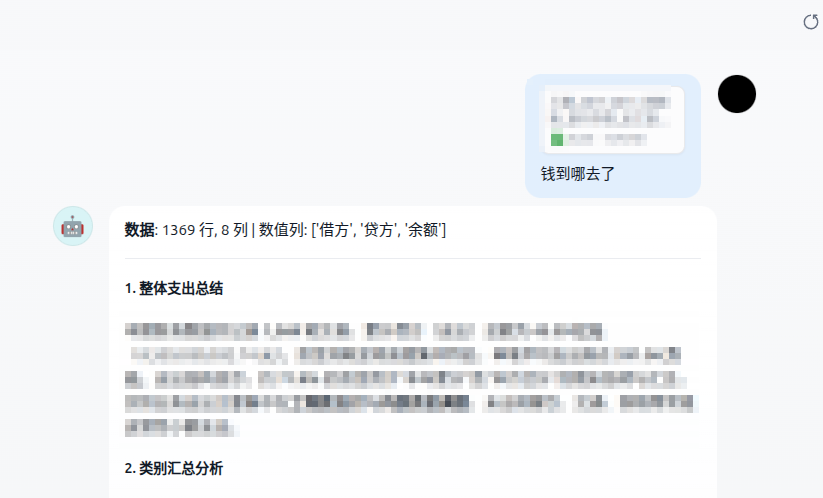
用户打开浏览器进入界面,上传一个Excel银行流水文件,工具会自动识别是哪家银行的格式、自动清洗数据、自动算好关键统计信息(多少行、多少列、数值列、支出对象Top、月度趋势等),然后就可以像聊天一样直接问问题了。

比如你上传一个"XX银行2017年流水.xlsx",然后输入"钱花哪了",AI会先把问题优化成一个专业的分析方案,确认后开始执行分析。跑完后就能看到AI给出的结论,支出最多的对象是谁、占多少比例、月度趋势有没有异常波动、整体资金状况是否健康。不满意还可以继续追问"那三月份是什么情况",能自动带上之前分析的上下文。
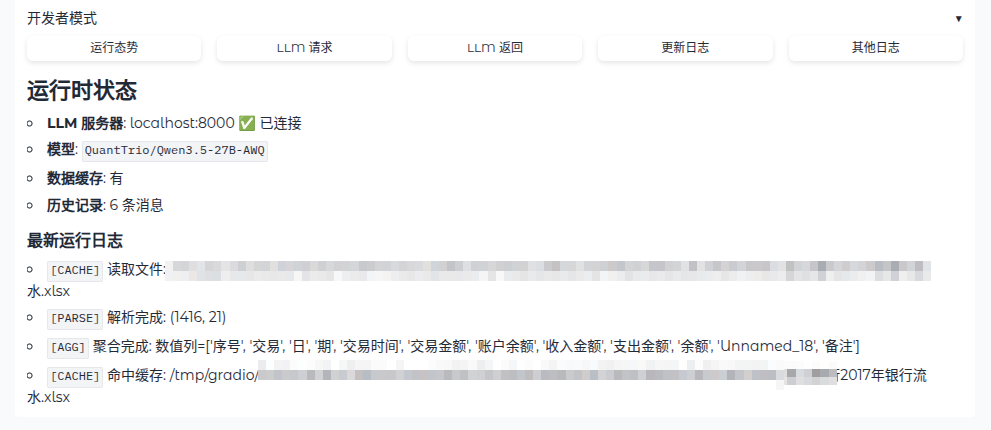
支持多会话管理,可以切换到之前的分析记录查看。支持全屏模式,看长分析结果不用拖滚动条。还有开发者模式,方便调试LLM的请求和返回报文。所有数据不离开本地,全程走内网localhost:8000的vLLM服务。
同时这套核心引擎也以FastAPI接口的形式暴露出来,注册到了Dify当外部工具用。也就是说既可以在浏览器里打开Gradio直接操作,也可以在Dify的工作流里拖一个"财务数据分析"节点来完成更复杂的自动化任务。同一个引擎,桌面端和Dify都能用。
顺手也写了个dify的流,客户想怎么用怎么用,问完这个转头问其他毫不相关的内容也能回答:

从想法到能用的版本大概花了四周。虽然还有很多不完善的地方——比如目前只适配几种常见流水格式,更多银行格式需要继续覆盖;目前输出是纯文本,没有可视化图表;不支持批量处理多个文件同时对比分析,但是客户给他一个文件能跑起来了,那就先这样(x
后面迭代更新的话再补)
Comments 1 条评论
学习大佬的思路