1.前情提要
前情提要:算了懒得讲了,直接看这个吧 https://yuluoxk.cn/yibosanzhe/
简而言之,突然发现服务器上不去了,经过一番排查发现是断网了。然后就开始了无穷无尽的排故之路(
2.事件复盘
2022.12.25 19:50 服务器突然cpu占用率,负载值升高。预测网络连接在6-8小时后断开,官网的图表此后便再无服务器数据。
2022.12.26 12:35突然想打开博客发个说说 突然发现打不开便开始排故
12 : 51 前往DO支持中心给工作人员发送工单尝试让他协助我排故
3.故障分析
BJT 当日晚间7:55分 支持人员回复工单要我提供以下输出:
# cat /etc/netplan/50-cloud-init.yaml
# cat /etc/network/interfaces
# cat /etc/udev/rules.d/70-persistent-net.rules
# ip addr
# ip route
# iptables -nvL --line-numbers
# ufw status verbose
# systemctl status networking.service
# systemctl status systemd-networkd
# systemctl status network输出如下:
[rootecentos-blog network-scripts]# cat /etc/netplan/50-cloud-init.yaml
cat: /etc/netplan/50-cloud-init.yaml: No such file or directory
[rootecentos-blog network-scripts]# cat /etc/network/interfaces
#Generated by the DigitalOcean provisioning process on 2022-12-21T12:09:25Z
#See 'man interf aces' on a DebianUbuntu systems.
# The network conf iguration was generated from http:/7169.254.169.254/metadata/v1.json.
#You may also find the it on the locally attached CDROM under 'digitalocean_meta_data.json'
auto lo
iface lo inet loopback
dns-nameservers 67.207.67.3 67.207.67.2
auto eth0
iface eth0 inet static
hwaddress cZ:3f:18:7a:33:2f
address 139.59.108.86
netmask 255.255.248.B
gateway 139.59.96.1
post-up ifup eth0:1
auto eth:1
if ace eth:1 inet static
huaddress cZ:3f:18:7a:33:2f
address 10.15.0.5/255.255.0.0
auto eth1
iface eth1 inet static
hwaddress f6:84:e3:16:50:fa
address 10.104.8.3
[rootecentos-blog network-scripts]# cat /etc/udev/rules.d/78-persistent-net.rules
SUBSYSTEM=="net",ACTION=="add",DRIUERS=="?*",ATTR{address}== "c2:3f:18:7a:33:2f ",NAME="eth0"
SUBSYSTEM== "net",fCTION="add",DRIUERS="?*",ATTRfaddress}== "f6:84:e3:16:50:fa",NAME="eth1"
[rootcentos-blog network-scripts]# ip addr
……
2: eth0:<BROADCAST,MLTICAST>mtu 1508 qdisc noop state DOWN group default qlen 1000
link/ether c2:3f:18:7a:33:2f brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
3: eth1:<BRDADCAST,MLTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether f6:84:e3:16:50:fa brd ff:ff:ff:ff:ff:ff
altname enp0s4
altname ens4
……
[rootCcentos-blog network-scripts]# ufw status uerbose
-bash: ufw: command not found
[rootecentos-blog network-scripts]# systemctl status networking.service
Unit networking.service could not be found.
[rootecentos-blog network-scripts]# systemctl status systemd-netuorkd
Unit systend-networkd.service could not be found.
lrootecentos-blog netuork-scripts]# systemctl status netuork
Unit netuork.service could not be found.
[roottcentos-blog netuork-scripts]# lip route
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1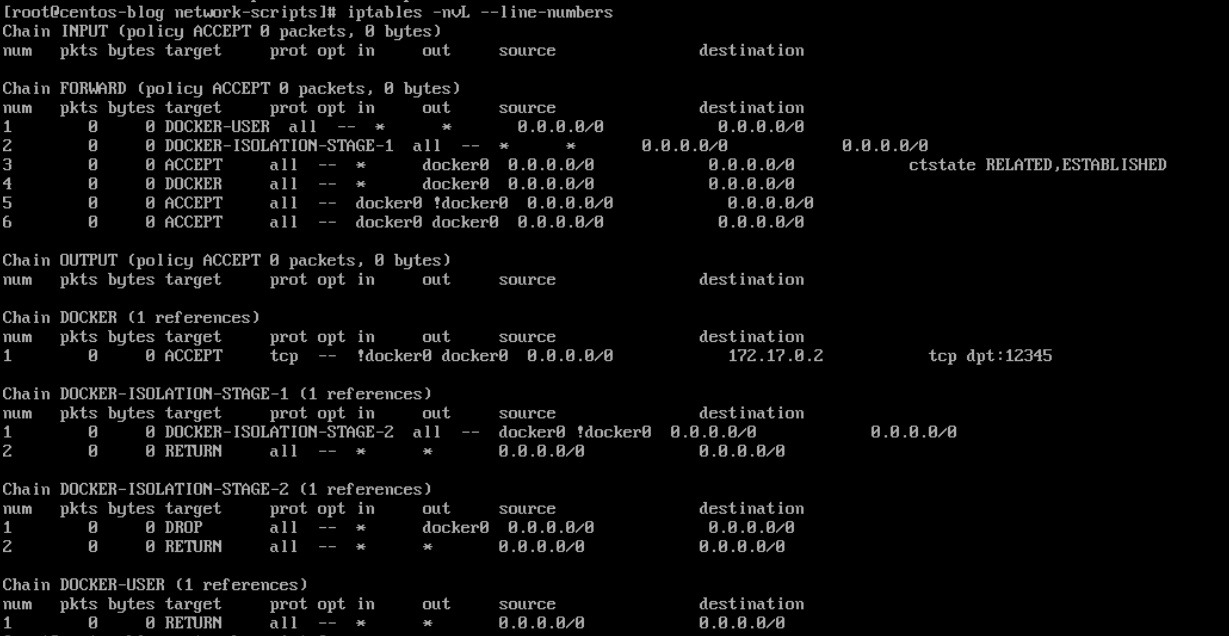
输出就这些,对Linux我掌握的也不深,完全看不懂()只能把结果发给支持人员等待进一步回复
在第二天的晚间早上1:25分 等来了回复:
I understand that you're experiencing issues with your Droplet's networking. We've reviewed the external factors that could impact your Droplet and aren't able to identify any issues that could impact its connectivity indicating that there's likely an internal configuration that needs to be addressed in order to restore connectivity.
It seems there is no default route being the cause for network disruption.
First, we would recommend reviewing the contents of your interface configuration file. From here you can ensure that there is an entry for your public interface and that it contains correct information including your public IPv4 address, gateway, netmask, etc. If needed, you can reference the information made available to you on the 'Networking' page of your Droplet or under your web console screen to ensure this information is correct. To work around this issue, you can manually set the route using the gateway listed in the Droplet networking tab with the following commands. You can also use your preferred text editor to add the "GATEWAY=<GATEWAY IP>" line to the ifcfg-eth0 file so that it gets set on reboot. Once the Droplet is able to connect, you will want to update your software ( typically "yum update" ) and ensure that the cloud-init package is updated to version 0.7.9 or higher.
If you are using a Snapshot to build out your Droplets, be sure to update the Snapshot to one with an updated cloud-init release to avoid this issue with future builds.
We hope this is helpful, though if you are not able to see a clear cause of this behaviour from this output, please feel free to provide us with screenshots of the output and we would be happy to help you review this. If you have any other questions or concerns, please don't hesitate to let us know.
If you have any further questions, please let us know. We're here to help!
# cat /etc/sysconfig/network-scripts/ifcfg-eth0 # ip route add default via 139.59.96.1
对面认为是网关问题,要我执行以上两条命令:
[rootecentos-blog ~]#cat /etc/sysconfig/network-scripts/ifcfg-eth0
# Created by cloud-init on instance boot automatically, do not edit.
#
AUTOCONNECT_PRIORITY=999
BOOTPROTO=none
DEFROUTE=yes
DEVICE=eth0
GATEWAY=139.59.96.1
HWADDR=c2:3f:18:7a:33:2f
IPADDR=139.59.108.80
IPADDR1=10.15.0.5
MTU=1500
NETMASK=255.255.240.0
NETMASK1=255.255.0.0
ONBOOT=yes
TYPE=Ethernet
USERCTL=no
[rootecentos-blog ~]# ip route add default via 139.59.96.1很可惜,没什么用。我只得再次将输出结果回复工单。
最后,我终于在晚上11:21分等到了回复:
Reviewing the output of the commands it appears that the public network interface is DOWN and the IP address is not configured, so we need to configure it and bring it up and add the default gateway as well to establish a working public route.
So in order to configure the public network interface please make sure to run the commands in the same order given below. You can use the Droplet recovery console to execute these commands.
This should establish a functional public route, though you may still need to add nameservers for hostname resolution. Use your preferred text editor to open /etc/resolv.conf and add Google’s DNS resolvers. The example below uses nano:$ ip addr add 139.59.108.80/20 dev eth0 $ ip link set eth0 up $ ip route add default via 139.59.96.1
nano /etc/resolv.conf
Add the following nameservers:
nameserver 8.8.8.8
nameserver 8.8.4.4
Please note that adding the route and manually raising the interface will not be persistent, so you will lose public networking again after reboot if the underlying issue with networking is not resolved. Similarly, nameservers manually added to /etc/resolv.conf will not be persistent either. So, once you are done with this, please share the output of the below commands so we can take further steps accordingly.
cat /etc/*release
cloud-init -v
ip addr
ip route
I hope this helps but feel free to write back if you have any concerns.
在根据支持人员所说正确配置公网接口之后,成功恢复网络连接。甚至都没配置DNS服务器。
SSH可以正常链接,BT面板也可以正常访问了。
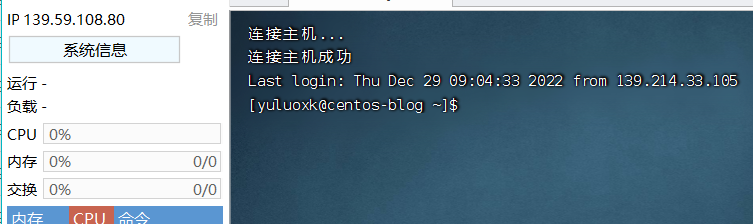
问题基本解决。但是仍不知道该问题是如何造成的。
只能等支持人员回复工单了(顺便还能再水一篇文章)
Comments NOTHING